

Nuclide spectrum feature extraction and nuclide identification based on sparse representation
-
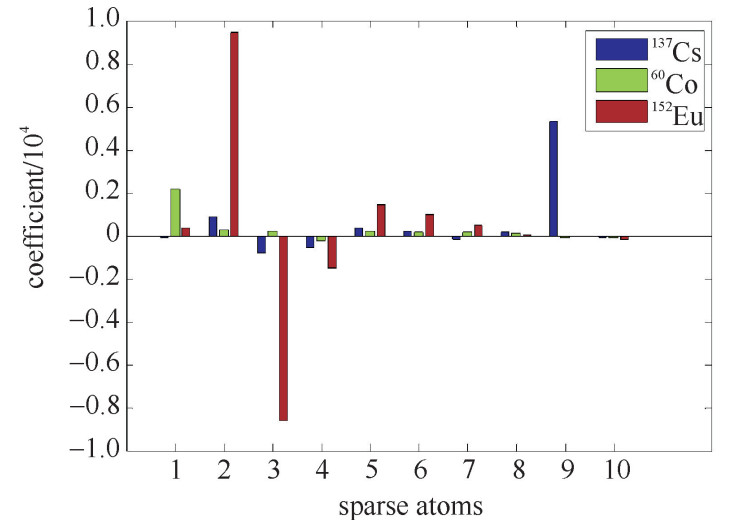
摘要: 提出了一种基于稀疏表示的核素能谱特征提取方法,其实质是将核素能谱在区分性最好的稀疏原子上进行投影。利用稀疏分解方法对核素能谱进行稀疏分解,提取分解系数向量作为表征核素的特征向量,通过模式识别分类方法建立分类模型实现核素识别。与传统稀疏分解方法的区别在于:在能谱稀疏分解过程中按照稀疏字典中的原子排列顺序顺次进行分解;其次,分解目的在于特征提取,即最终提取到的特征对不同核素具有可区分性,并不要求核素能谱的重构精度。在241Am, 133Ba, 60Co, 137Cs, 131I和152Eu共6种核素1200个能谱数据上进行了核素识别实验,7种不同分类算法的平均识别率达到91.71%,实验结果的统计分析表明,本文提出的特征提取方法识别准确率显著地高于两种传统核素能谱特征提取方法准确率。Abstract: A sparse representation based method for nuclide spectrum feature extraction is proposed. The essence of this method is to decompose the energy spectrum on the best distinguishable sparse atom. The sparse decomposition method is used to decompose the nuclide energy spectrum, and the decomposition coefficient vector is taken as the feature to represent the energy spectrum. The classification model is established by the pattern recognition algorithm to realize the nuclide identification. The main difference from the traditional sparse decomposition method is that we decompose the energy spectrum in accordance with the sparse atoms in the sequential order in sparse dictionary. In the experiments, 6 kinds of radionuclide including 241Am, 133Ba, 60Co, 137Cs, 131I and 152Eu, 1200 energy spectra are used and the average nuclide identification accuracy on 7 different pattern recognition algorithms is 91.71%. The results of statistical tests show that the proposed algorithm performs significantly better than two traditional nuclide spectrum feature extraction methods.
-
表 1 三种特征提取方法在模拟核素上的识别结果
Table 1. Classification results of the three feature extraction methods
methods sparse representation(rank) SG +derivative(rank) TS+derivative(rank) KNN 97.11%(1) 88.75% (2) 72.67% (3) NavieBayes 88.57%(1) 44.58% (2) 38.92% (3) SMO 72.86%(1) 19.50% (3) 21.83% (2) PART 96.00%(1) 91.25% (2) 78.00% (3) J48 96.86%(1) 90.83% (2) 74.42% (3) CART 96.29%(1) 89.50% (2) 76.00% (3) RBFNetwork 94.29%(1) 73.17% (2) 58.00% (3) mean 91.71%(1) 71.08%(2.14) 59.98%(2.86)  下载: 导出CSV
下载: 导出CSV
表 2 Holm检验
Table 2. Holm test
i methods z=(Ri-R1)/SE p α/(k-i) 1 TS+derivative peak seeking (2.86-1)/0.535 4=3.479 7 0.000 5 0.025 0 2 SG+derivative peak seeking (2.14-1)/0.535 4=2.132 7 0.032 9 0.050 0
下载: 导出CSV
-
[1] Portnoy D, Fisher B, Phifer D. Data and software tools for gamma radiation spectral threat detection and nuclide identification algorithm development and evaluation[J]. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 2015, 784: 274-280. doi: 10.1016/j.nima.2014.11.010 [2] Burr T, Hammada M. Radio-isotope identification algorithms for NaI γ spectra[J]. Algorithms, 2009, 2(1): 339-360. doi: 10.3390/a2010339 [3] Uher J, Roach G, Tickner J. Peak fitting and identification software library for high resolution gamma-ray spectra[J]. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 2010, 619(1): 457-459. [4] 易义成, 宋朝晖, 管兴胤, 等. 溴化镧高剂量率线性响应范围的测定[J]. 强激光与粒子束, 2016, 29: 096002. doi: 10.11884/HPLPB201628.151241Yi Yicheng, Song Chaohui, Guan Xingying, et al. Measurement of linear response upper limit for LaBr3 to pulsed gamma radiation. High Power Laser and Particle Beams, 2016, 29: 096002 doi: 10.11884/HPLPB201628.151241 [5] 安力, 何铁, 郑普, 等. 伴随粒子法γ能谱本底测量技术[J]. 强激光与粒子束, 2013, 25(11): 3045-3049. doi: 10.3788/HPLPB20132511.3045An Li, He Tie, Zheng Pu, et al. Research on γ background spectra in associated particle technique. High Power Laser and Particle Beams, 2013, 25(11): 3045-3049 doi: 10.3788/HPLPB20132511.3045 [6] 何剑锋. 低能量分辨率γ能谱数据解析方法研究[D]. 成都: 成都理工大学, 2013.He Jianfeng. A study for decomposition method of lower-energy resolution gamma-energy resolution gamma-ray spectra data. Chengdu: Chengdu University of Technology, 2013 [7] Mallat S, Zhang Z. Matching pursuits with time-frequency dictionaries[J]. IEEE Trans on Signal Processing, 1993, 41(12): 3397-3415. doi: 10.1109/78.258082 [8] Aha D, Kibler D, Albert M. Instance-based learning algorithms[J]. Machine Learning, 1991, 6(1): 37-66. [9] George H, Langley P. Estimating continuous distributions in Bayesian classifiers[C]//Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, 1998: 338-345. [10] Platt J. Fast training of support vector machines using sequential minimal optimization[M]. Massachusetts: MIT Press, 1999: 185-208. [11] Frank E, Witten I. Generating accurate rule sets without global optimization[C]//The Fifteenth International Conference on Machine Learning. 1998: 144-151. [12] Quinlan J. C4.5: programs for machine learning[M]. San Francisco: Morgan Kaufmann Publishers, 1993. [13] Breiman L, Friedman J, Olshen R, et al. Classification and regression trees[M]. Boca Raton: CRC Press, 1984. [14] Bouchoux S, Paindavoine M. Implementation of pattern recognition algorithm based on RBF neural network[C]//Proc of SPIE. 2002, 8(18): 4572-4581. [15] Demsar J. Statistical comparisons of classifiers over multiple data sets[J]. Journal of Machine Learning Research, 2006, 7: 1-30. -
 点击查看大图
点击查看大图
图(1) / 表(2)
计量
- 文章访问数: 1794
- HTML全文浏览量: 444
- PDF下载量: 230
- 被引次数: 0
