

252Cf-source-driven nuclear material concentration identification based on deep learning
-
摘要: 针对核武器/核材料识别系统中核材料浓度识别的关键技术问题,采用Monte Carlo方法,通过建立252Cf源驱动核材料裂变中子信号样本库,模拟分析了随探测器距离和角度及核材料浓度变化的裂变脉冲中子信号特点,基于深度学习之卷积神经网络,构建了一种252Cf源驱动核材料浓度识别方法,实现了对测试样本浓度的识别,且还与BP神经网络和K最近邻方法进行了对比试验研究。结果表明,卷积神经网络算法进行核材料浓度识别,得到了高达92.05%识别准确率,不仅解决了因探测器距离和角度变化时对核材料浓度识别准确率影响的难题,而且还获得了优于BP神经网络和K最近邻算法对核材料浓度识别的认识,这为252Cf源驱动核材料浓度识别提供了一种新的途径。Abstract: For the problem of concentration identification of nuclear material in nuclear weapon/material identification system, we used the Monte Carlo method, established a database of neutron signal obtained by fission of nuclear material driven by 252Cf-source under the condition of different distance and angle of detectors. Based on the convolutional neural network in deep learning area, a method for 252Cf-source-driven nuclear material concentration identification was constructed, thereby, the identification of test samples was realized. Then a contrast experiment was conducted with the BP neural network and K-nearest neighbor method. The experimental results show that using the constructed method, a high identification rate of 92.05% is got. The problem of the accuracy of the nuclear material concentration identification was affected by the change of the distance and angle of the detector is solved, and the accuracy of this method is better than that of the BP neural network and K-nearest neighbor methods. This paper provides a new idea for the 252Cf-source-driven nuclear material concentration identification.
-
核武器的存在与核技术的发展所产生的一系列不确定因素,凸显了当今世界核扩散的潜在威胁,从而引发了国际关系中被反复涉及的防止核扩散这一重大课题。迄今为止,防止核扩散的唯一有效技术手段即是核军控核查[1]。
目前,核军控核查技术的诸多手段中,核武器/核材料识别系统(NWIS/NMIS)[2-3]不仅可快速、准确地识别核材料浓度(即核材料中某易裂变元素的质量分数),而且还摒弃了通过感应核材料或核部件的固有辐射来获取特征信息的被动式测量方法的弊端。它是一种基于252Cf源作为驱动中子源的随机中子脉冲核噪声分析的主动式测量方法,故而备受青睐。基于此方法,还衍生了一系列核材料浓度识别的方法技术。例如,文献[4]利用Elman神经网络对不同浓度核材料进行分析与识别;文献[5]将高阶统计特征概念引入252Cf源驱动核系统中,以此进行特征提取、分析与识别;文献[6]研究了一种基于压缩感知的K最近邻核材料浓度识别方法。上述这些技术或方法虽获得了较高的识别精度,但因均是小样本实验,容易受探测器距离和角度变化因素影响,致使识别精度难以取得实质性突破。
近年来,深度学习[7]已经广泛应用于图像识别、语音识别、自然语言处理等各个方面[8-10]。作为深度学习方法之一的卷积神经网络,因其特殊的网络结构,在大规模的数据评测中近期取得了非凡的成绩。A.Krizhevsky等人[11]首次将卷积神经网络应用于ImageNet大规模视觉识别挑战赛,取得了图像分类和目标定位任务的第一名。香港中文大学的DeepID2项目[12]采用卷积神经网络,将人脸识别率提高到了99.15%,超过之前所有的人脸识别方法。文献[13]还将卷积神经网络用于解决心电图T波形态分类问题,取得了99.1%的识别精度。然而,迄今,将深度学习之卷积神经网络方法技术应用于核材料的浓度识别,尚未见相关文献报道。
有鉴于此,本文借助于Monte Carlo方法模拟核材料识别系统,通过获取不同距离与角度探测器探测到浓度不一的含235U核材料裂变中子信号,以此建立252Cf源驱动核材料裂变随机脉冲中子信号库。基于此,构建了卷积神经网络,开展了252Cf源驱动核材料浓度分类识别研究工作。实验结果表明,本文所述核材料浓度识别方法,解决了核材料浓度识别中探测器距离和角度变化的问题,且识别准确率优于BP神经网络和K最近邻等方法,为核材料识别提供了一种新的技术方法或手段。
1. 基本测量原理
基于252Cf源驱动随机中子脉冲核噪声分析法,是一种主动式测量方法,其典型测量方法乃是基于252Cf源驱动的三通道裂变中子脉冲信号测量系统,如图 1所示。此系统由252Cf中子源、钢罐、铀铸件、探测器等组成,其中,铀铸件即为核材料。252Cf源作为驱动源,其一次自发裂变约产生4个中子与6个γ光子,产生的中子进入铀铸件发生散射、吸收及诱发裂变,每个235U原子一次裂变产生2~4个中子及若干γ光子,产生的中子进一步诱发后续的235U原子裂变形成裂变链,中子及光子会同时被探测器计数作为裂变中子信号。图 1(a)为测量系统正视图,左侧为源探测器,主要探测源信号,以分析源的一些特性。图 1(b)测量系统俯视图,右侧上、下放置两个探测器,它们会同时靠近或远离钢罐,以及绕钢罐旋转,以采集不同位置的信号。这样,构造了252Cf源驱动的三通道裂变中子脉冲信号测量系统。
 图 1 252Cf源驱动的三通道裂变中子脉冲信号测量系统示意图Figure 1. Measurement model of 252Cf source spectrum measurement system
图 1 252Cf源驱动的三通道裂变中子脉冲信号测量系统示意图Figure 1. Measurement model of 252Cf source spectrum measurement system2. 材料与方法
2.1 参数设定
依据图 1所示,可以建立核材料裂变脉冲中子信号库。实际上,由于库的建立涉及核材料浓度、探测器距离与角度等诸多变量,这将需要较多的核材料样本以及进行多次的信号探测,从而涉及到核材料使用的敏感性和强放射性的危害。为此,本文借助于国际上通用的MCNP5模拟工具软件,通过编写MCNP程序进行模拟核材料裂变中子脉冲信号。基于此,通过编写曲面卡与栅元卡定义系统几何结构,通过编写材料卡定义各材料属性、粒子输运方式及探测器计数方式。
这里,进行了系统的模拟参数设定。252Cf源设为点源,裂变率为6.14×105/(s·μg),每次裂变发射约4个中子与6个光子,其自发裂变中子能量分布谱服从Watt分布,即
f(E)=cexp(−Ea)sin(bE)12 (1) 式中:参数a为1.025;b为2.926;c为常量;E为出射中子能量,在式(1)中为自变量,出射中子平均能量2.348 MeV。模拟时,设置自发裂变中子事件数为24 560 000。
铀铸件放置于钢罐中,铸件高15.24 cm,内径8.89 cm,外径15.24 cm,成分为235U,238U,234U,236U,其中234U浓度为0.97%,236U浓度为0.24%,两者的浓度保持不变,235U与238U浓度之和为98.79%,238U浓度随235U浓度的变化而变化。钢罐高22.4 cm,外径15.6 cm,厚为0.15 cm。本文将模拟BC430塑料闪烁探测器,探测器长度设定为0.3 cm,宽和高均为10.16 cm,长度远小于宽度与高度,目的是防止MCNP程序运行时一个中子被多个探测器计数。探测器探测效率设置为100%。本文计数方式为每ns对中子与光子计数一次,总计数100 ns,将100个信号作为一个样本数。
基于设定的参数,通过改变核材料浓度,探测器离钢罐中轴距离以及绕钢罐中轴旋转角度,即可建立核材料裂变中子信号库,此可作为深度学习之卷积神经网络进行核材料浓度识别的样本。本文将样本分为训练样本与测试样本,两种样本对应的信号采集系统将由于如图 1(b)所示右侧探测器放置规律以及核材料浓度的取值规律会有所不同。
训练样本的获取时,探测器摆放位置及浓度取值:①探测器绕钢罐中轴旋转角度为0°,10°,20°,30°,40°,50°,60°,70°,80°和90°;②探测器离钢罐中轴距离为8,12,16,20,24,28和32 cm;③235U浓度,取整数值为3%~26%,30%,35%,40%,45%,50%,55%,56%,60%,65%,70%,75%,80%~95%。
测试样本的获取相对复杂,既要保证随机性以测试网络的性能,又要考虑到实际应用中对不同浓度核材料的使用频度,以便相应地做出一些选取,综合考虑可使样本数在浓度小于20%及大于90%范围内稍稍偏多。基此,探测器摆放位置及核材料浓度取值为:①探测器离钢罐中轴距离8,18,24和30 cm;②旋转角度为0°,20°,45°,60°和80°时,235U浓度变化为4%,8%,13%,18%,37%,58%,84%,87%,90%,92%和94%;③旋转角度为15°,35°,55°,75°和90°时,235U浓度变化为5%,11%,16%,28%,43%,70%,85%,88%,91%,93%和95%。
需要指出的是,为了避免对裂变中子信号的描述过于繁琐且方便表示,本文规定用4维数组(信号、距离、浓度、角度)表示以上信息,按时间、距离、浓度、角度由小到大,相对应地用从1开始的数字表示,例如,训练样本(1, 2, 3, 4)表示探测器在第30°,距离为12 cm时,对浓度为5%铀铸件探测到的第1 ns的信号。这样,最终有3570个训练样本与440个测试样本,用于后续卷积神经网络的构建与测试。
2.2 卷积神经网络识别核材料浓度
2.2.1 卷积神经网络及其构建流程
当今,卷积神经网络是众多学者所青睐的深度学习算法,它是一种典型的有监督前馈神经网络,集特征提取与分类于一体,这样的优异性能得益于三大特点,即局部感知、权重共享及下采样操作。输入到网络中的数据,经过若干次卷积处理、非线性变换及下采样操作之后,可以通过全连接层最后输出到网络。网络的参数调节,乃可通过反向传播算法借以实现。这里,需要注意的是,在卷积神经网络中,卷积层与下采样层的连接参数和下采样层与卷积层的连接参数的调整方法将会有所不同。本文将基于此工作原理构建卷积神经网络,用于核材料浓度识别,如图 2所示。
由此可见,虽然上述几个参数的确定尚不能最终确定一个网络,但是它们是网络中几个重要的参数。因此,一旦这几个参数确定之后,通过类似控制变量的方法确定其他参数,便能构建出一个较好的卷积神经网络。
2.2.2 核材料浓度识别流程
依据前述所构建的流程设计实验,可以构建出卷积神经网络进行核材料浓度的识别,它主要包括裂变中子信号库的建立、卷积神经网络的构建和核材料浓度识别,如图 3所示。
 图 3 核材料浓度识别流程原理框图Figure 3. Flow chart of nuclear material concentration identification
图 3 核材料浓度识别流程原理框图Figure 3. Flow chart of nuclear material concentration identification3. 实验结果与分析
3.1 裂变中子信号库的建立
通过设定的参数编写MCNP程序,运行后,得到训练与测试样本,图 4~6为一部分训练样本的结果。如图 4所示,探测器距离钢罐中轴为16 cm,235U浓度为85%,探测器角度分别取10°,30°,50°,70°,80°,90°时,1~60 ns粒子计数的分布。可见,曲线的幅度先减小后增大,这使得不同的核材料浓度在不同的角度获得的曲线可能极为相似。图 5为探测器距离钢罐中轴为16 cm,235U浓度分别为3%,13%,23%,56%,85%,95%,探测器角度取0°时,1~60 ns粒子计数的分布。可见,当235U浓度改变时,曲线的变化并不大。图 6显示了探测器距离钢罐中轴为8,16,24,32 cm,235U浓度为85%,探测器角度取0°时,1~60 ns粒子计数的分布。可以看出,曲线的幅度随距离的变化有较大的改变,远大于曲线幅度随浓度的变化,最大峰值与最小峰值相差两个数量级。
 图 4 训练样本计数时域分布随角度变化示意图Figure 4. Count distribution of training samples varies with angle
图 4 训练样本计数时域分布随角度变化示意图Figure 4. Count distribution of training samples varies with angle 图 5 训练样本计数时域分布随浓度变化示意图Figure 5. Count distribution of training samples varies with concentration
图 5 训练样本计数时域分布随浓度变化示意图Figure 5. Count distribution of training samples varies with concentration 图 6 训练样本计数时域分布随距离变化示意图Figure 6. Count distribution of training samples varies with distance
图 6 训练样本计数时域分布随距离变化示意图Figure 6. Count distribution of training samples varies with distance3.2 卷积神经网络的构建
3.2.1 数据预处理
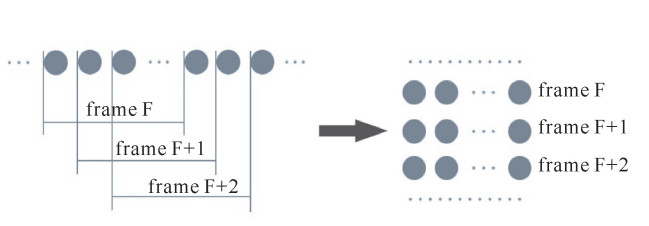
为了达到卷积神经网络对输入数据的要求,拟首先将每一个样本进行分帧处理以此得到一个二维的数据,如图 7所示。从分析样本信号可知,不同样本信号前2个以及第70个以后数值大小基本相等,对网络的训练作用甚微。于是,按图 7所示方法,第一帧从第三个信号开始,取帧长为24,帧移为2,得到24×24的二维信号。
接着,标准化数据以减小由于数据取值范围过大对训练收敛速率的影响。实验中,采用min-max标准化,即
X∗=x−xminxmax−xmin (2) 式中: x为待标准化值;xmax为所有数据中最大值;xmin为所有数据中最小值。这样,便可将标准化的信号作为卷积神经网络的输入参数。
3.2.2 网络结构初始化
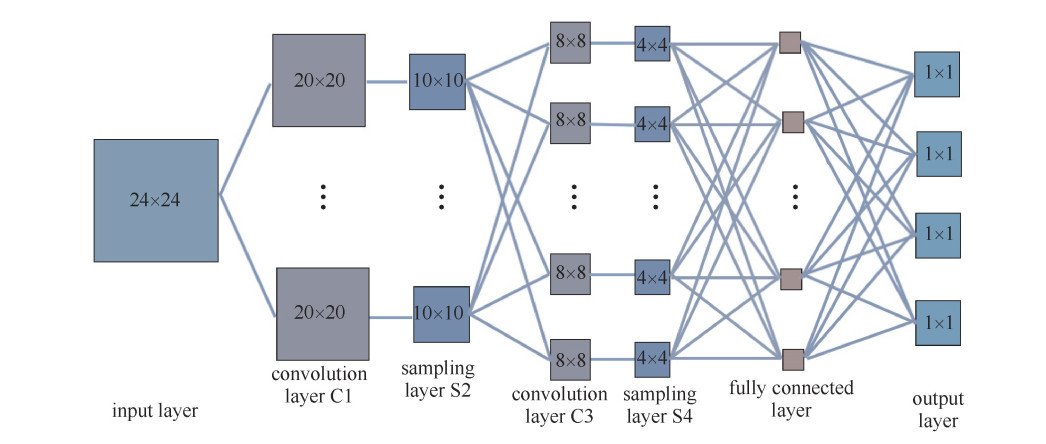
初始化网络结构,如图 8所示。这里,输入层为24×24二维数组,输入层到第一个卷积层C1,取卷积核数为6,卷积核大小5×5,第一个卷积层C1到下采样层S2用均匀池化。第一个下采样层S2到第二个卷积层C3卷积核数仍然为6,卷积核大小3×3。第二个卷积层C3到下采样层S4采用均匀池化。第二个下采样层S4后设置全连接层,数量为140。最后,是输出层,有4个神经元。本网络激活函数均使用Sigmoid函数。对于每一次迭代,将训练样本分块进行,每块有51个样本。网络训练采用梯度下降法,目标函数使用均方误差函数,权值更新时加入动量项,学习率随着迭代次数增加逐渐减小。
3.2.3 确定权值调节因子
首先,初始化动量因子为0.8,学习率为0.1。除卷积层到下采样层,其余层间连接均设置权值,权值初始化采用经验公式
w=a√6√ηin +ηout d (3) 式中: w为计算出的权值;a为-0.5~0.5的随机数;ηin和ηout分别为输入与输出神经元个数;d为权值调节因子。改变权值调节因子,观察分类错误率的变化,均迭代210次且取最后10次迭代中错误率最小的一个值,结果如图 9所示。由此可以看出,当权值调节因子取8,10,12,14时,获得较小分类错误率。
 图 9 权值调节因子取不同值的分类错误率Figure 9. Classification error rate varies with weight adjustment factor
图 9 权值调节因子取不同值的分类错误率Figure 9. Classification error rate varies with weight adjustment factor3.2.4 确定学习率
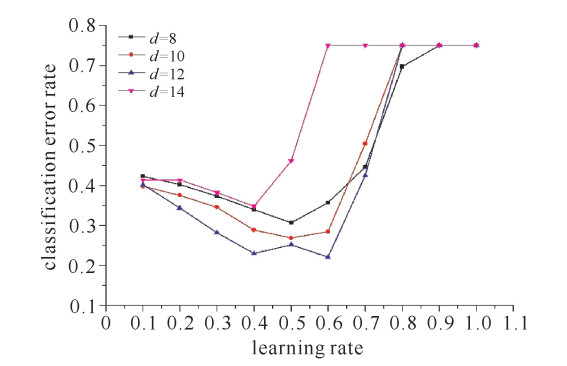
依次取权值调节因子为8,10,12,14,改变学习率,观察分类错误率的变化。迭代210次,取最后10次迭代中错误率最小的值,结果如图 10所示。由此可见,分类错误率0.75,表示网络不收敛。因此,当学习率取值较大时,不利于网络的收敛。当权值调节因子取12,学习率取0.4,0.5和0.6时,分类错误率较小。
3.2.5 确定卷积核数量
保持第二个卷积层卷积核数不变,改变第一个卷积层卷积核数,观察分类错误率的变化。将权值调节因子设定为12,学习率取一个较小的值0.4,为保证网络能够收敛,将动量因子减小到0.7。迭代510次,取最后10次迭代中错误率最小的一个值,结果如图 11所示。由此可见,第一个卷积层卷积核数取6时,分类错误率较小,这里,没有考虑积层卷积核数大于6的情况,一般情况下,卷积神经网络中前面卷积层的卷积核数要小于后面卷积层,更多情况可后续尝试。
 图 11 卷积核取不同个数的分类错误率Figure 11. Classification error rate varies with number of kernels
图 11 卷积核取不同个数的分类错误率Figure 11. Classification error rate varies with number of kernels综上所述,可以初步确定网络的权值调节因子为12,动量因子为0.7,学习率初值为0.4,两个卷积层卷积核数量均为6。至此,卷积神经网络的所有参数均已确定。
3.3 核材料浓度识别实验
首先,通过前述构建的网络,进行了核材料浓度分类识别实验。其次,为判别卷积神经网络在浓度识别方面性能的优劣,设计了BP神经网络与K最近邻方法核材料浓度识别实验,借以对比实验结果。
3.3.1 卷积神经网络识别实验
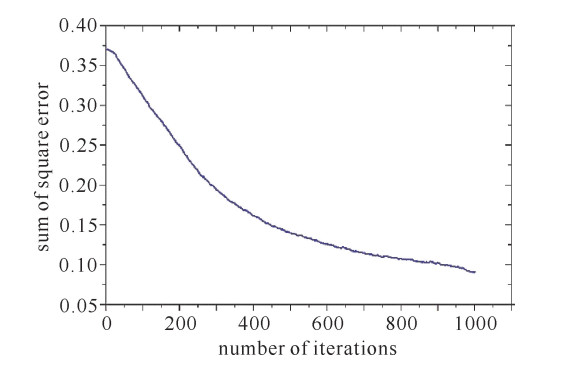
设置学习率为每迭代400次减少0.1,训练结束条件为当对测试样本的分类错误率小于8%时停止迭代,同时设置最大迭代次数1200次。当迭代913次时,测试样本分类精度达到要求,得到网络对测试样本的分类错误率为7.95%,对训练样本的分类错误率为9.02%,网络损失函数曲线,如图 12所示。
3.3.2 BP神经网络识别实验一
通过选取sym4小波基,Shannon熵,对每个样本的前80个信号进3层小波包分解,获得每个样本的时频特征,通过求解每个系数的能量值,得到每个样本的8维特征向量,以供BP神经网络使用。
构建BP神经网络,使其有两个隐含层,分别有40与20个神经元。激活函数从输入到输出依次为tanh,tanh与sigmoid。取学习率为0.8,使用共轭梯度法进行训练。经过3000次迭代后,得到分类错误率为37.95%。
3.3.3 BP神经网络识别实验之二
考虑到特征选取方法对识别准确率的影响,本文将提取另外一种特征。对每个样本第3到第68个信号,按3个一组分为22组,分别取每组平均值作为特征值,得到每个样本的22维特征向量,以供BP神经网络使用。构建BP神经网络,使其有两个隐含层,分别有60与40个神经元。激活函数从输入到输出依次为tanh,tanh与sigmoid。取学习率为0.8,使用共轭梯度法进行训练。经过3000次迭代后,得到分类错误率为12.73%。
3.3.4 K最近邻方法识别实验
利用K最近邻方法,再次对核材料浓度进行识别。本文选取欧氏距离作为样本间距离的评估。通过实验得到,当K取7时,则有最低的分类错误率为37.5%。
3.4 实验结果分析
通过前述实验综合分析,可以获得各个实验对测试样本识别准确率,如表 1所示。在卷积神经网络识别实验中,网络对测试样本的分类准确率,略高于对训练样本的分类准确率,这是因为人为地将测试样本较高地集中于低富集与超富集范围,提高了测试样本的识别精度。利用BP神经网络进行的两次实验,不同的特征提取方法得到的结果差异比较大,此方法使得比较结果更加可靠。即神经网络识别实验一与实验K最近邻方法识别实验得到的结果精度较低,虽然BP神经网络识别实验之二得到的精度较高,但仍然低于卷积神经网络识别实验得到的结果。本文几个实验迭代次数均很大,原因在于样本数据随浓度变化差异较小,随探测器距离与角度变化差异较大。另外,标准化数据之后,最小值与最大值相差4个数量级,数据大小的差异使得迭代次数增大。
表 1 不同实验得到的分类准确率一览表Table 1. Classification accuracy of different experimentsexperiment error/% convolutional neural network 7.95 BP neural network feature Ⅰ 37.95 BP neural network feature Ⅱ 12.73 K-nearest neighbor 37.5 4. 结论
本文借助Monte Carlo方法建立核材料裂变中子信号库,将库中的信号作为样本,并对深度学习之卷积神经网络进行训练与测试。通过研究,其结论是:利用训练好的卷积神经网络,可以识别不同距离及角度的探测器探测到的裂变中子信号,以此实现对不同浓度的核材料进行识别,其识别准确率可达92.05%。这不仅揭示了卷积神经网络用于识别核材料浓度的可行性,还显示了该算法较之于BP神经网络与K最邻近方法进行核材料浓度识别的优良性能,可以为核材料浓度识别提供一种新的途径或技术方法。
-
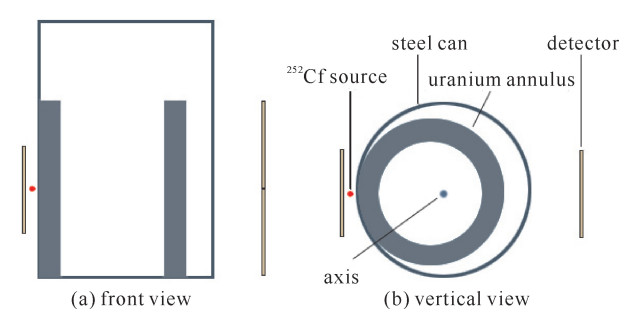
图 1 252Cf源驱动的三通道裂变中子脉冲信号测量系统示意图
Figure 1. Measurement model of 252Cf source spectrum measurement system

图 3 核材料浓度识别流程原理框图
Figure 3. Flow chart of nuclear material concentration identification
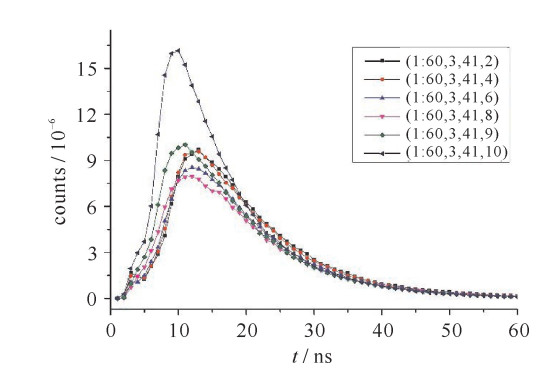
图 4 训练样本计数时域分布随角度变化示意图
Figure 4. Count distribution of training samples varies with angle
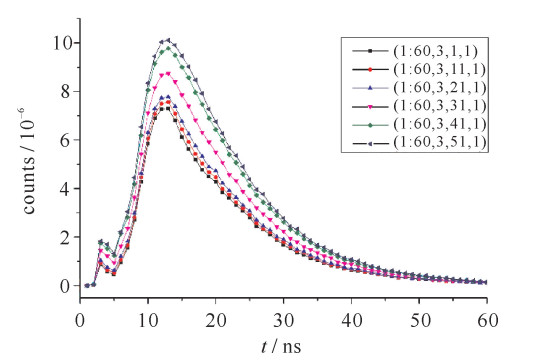
图 5 训练样本计数时域分布随浓度变化示意图
Figure 5. Count distribution of training samples varies with concentration
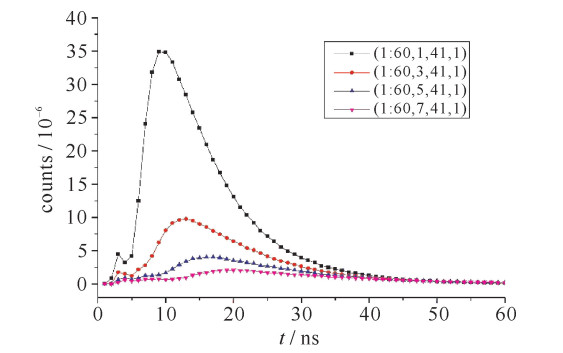
图 6 训练样本计数时域分布随距离变化示意图
Figure 6. Count distribution of training samples varies with distance
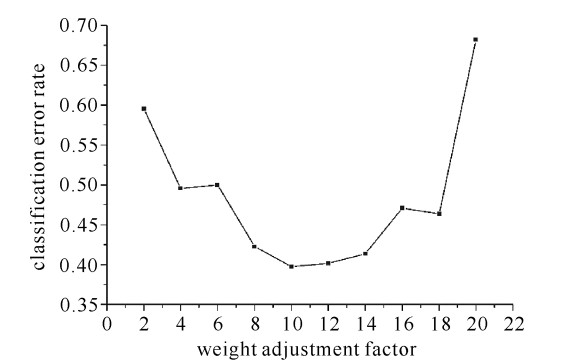
图 9 权值调节因子取不同值的分类错误率
Figure 9. Classification error rate varies with weight adjustment factor
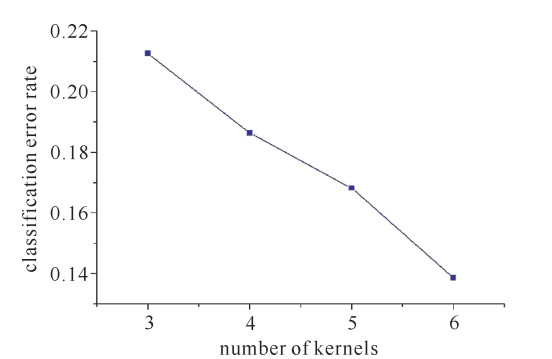
图 11 卷积核取不同个数的分类错误率
Figure 11. Classification error rate varies with number of kernels
表 1 不同实验得到的分类准确率一览表
Table 1. Classification accuracy of different experiments
experiment error/% convolutional neural network 7.95 BP neural network feature Ⅰ 37.95 BP neural network feature Ⅱ 12.73 K-nearest neighbor 37.5  下载: 导出CSV
下载: 导出CSV
-
[1] 刘成安, 伍钧. 核军备控制核查技术概论[M]. 北京: 国防工业出版社, 2007: 26-40.Liu Cheng'an, Wu Jun. Nuclear arms control and verification technology concept. Beijing: National Defense Industry Press, 2007: 26-40 [2] Mihalczo J T, Valentine T E, Mullens J A, et al. Physical and mathematical description of nuclear weapons identification system(NWIS) signatures[R]. The US Department of Energy Report No. Y/LB-15, 1997. [3] Mattingly J K, Valentine T E, Mihalczo J T. NWIS measurements for uranium metal annular castings[R]. The US Department of Energy Report No. Y/LB-15, 1998. [4] 冯鹏, 刘思远, 米德伶. 基于Elman神经网络的252Cf源和系统随机中子脉冲信号识别方法[J]. 强激光与粒子束, 2011, 23(8): 2224-2228. http://www.hplpb.com.cn/article/id/5395Feng Peng, Liu Siyuan, Mi Deling. Identification of stochastic neutron pulse signal of 252Cf nuclear system based on Elman neural network. High Power Laser and Particle Beams, 2011, 23(8): 2224-2228 http://www.hplpb.com.cn/article/id/5395 [5] 杨帆, 魏彪, 冯鹏, 等. 互相关及高阶谱核材料富集度识别方法[J]. 强激光与粒子束, 2013, 25(4): 1026-1030. http://www.hplpb.com.cn/article/id/7415Yang Fan, Wei Bao, Feng Peng, et al. Nuclear material enrichment identification method based on cross-correlation and high order spectra. High Power Laser and Particle Beams, 2013, 25(4): 1026-1030 http://www.hplpb.com.cn/article/id/7415 [6] 李鹏程, 魏彪, 冯鹏, 等. 基于压缩感知的252Cf源驱动核材料浓度识别技术研究[J]. 强激光与粒子束, 2015, 27: 074004. doi: 10.11884/HPLPB201527.074004Li Pengcheng, Wei Biao, Feng Peng, et al. 252Cf-source-driven nuclear material concentration identification based on compressive sensing. High Power Laser and Particle Beams, 2105, 27: 074004 doi: 10.11884/HPLPB201527.074004 [7] 李玉鑑, 张婷. 深度学习导论及案例分析[M]. 北京: 机械工业出版社, 2016: 1-116.Li Yujian, Zhang Ting. Introduction to depth learning and case analysis. Beijing: China Machine Press, 2016: 1-116 [8] Song I, Kimht J, Jeon P B. Deep learning for real-time robust facial expression recognition on a smart phone[C]//Proceedings of the 2014 IEEE International Conference on Consumer Electronics. 2014: 564-567. [9] Mesnil G, Dauphin Y, Yao K, et al. Using recurrent neural networks for slot filling in spoken language understanding[J]. IEEE Trans on Audio Speech and Language Processing, 2105, 23(3): 530-539. [10] Dahl G E, Yu D, Deng L, et al. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition[J]. IEEE Trans Audio, Speech, and Language Processing, 2012, 20(1): 30-42. doi: 10.1109/TASL.2011.2134090 [11] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Conference on Neural Information Processing Systems. 2012: 1097-1105. [12] Sun Yi, Wang Xiaogang, Tang Xiaoou. Deep learning face representation by joint identification-verification[J]. International Conference on Neural Information Processing Systems, 2014, 27: 1988-1996. [13] 刘明, 李国军, 郝华青, 等. 基于卷积神经网络的T波形态分类[J]. 自动化学报, 2016, 42(9): 1339-1346. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201609005.htmLiu Ming, Li Guojun, Hao Huaqing, et al. T wave shape classification based on convolutional neural network. Acta Automatica Sinica, 2016, 42(9): 1339-1346 https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201609005.htm 期刊类型引用(3)
1. 宋孝宗,姚统,徐国敏. TiO_2纳米颗粒胶体活化系统设计及流场仿真分析. 兰州理工大学学报. 2020(03): 75-80 .  百度学术
百度学术2. 徐国敏,戴旭杰,姚统,宋孝宗. 余弦光-液耦合喷嘴参数优化及射流抛光实验. 现代制造工程. 2019(05): 52-56 . 百度学术3. 张航航,宋孝宗. 矩形光液耦合喷嘴的流场特性分析. 制造业自动化. 2019(12): 31-35 . 百度学术其他类型引用(4)
-

 下载:
下载:












 点击查看大图
点击查看大图
计量
- 文章访问数: 924
- HTML全文浏览量: 208
- PDF下载量: 293
- 被引次数: 7
