

Application of deep convolutional neural network in detection of nuclear waste in radiation environment
-
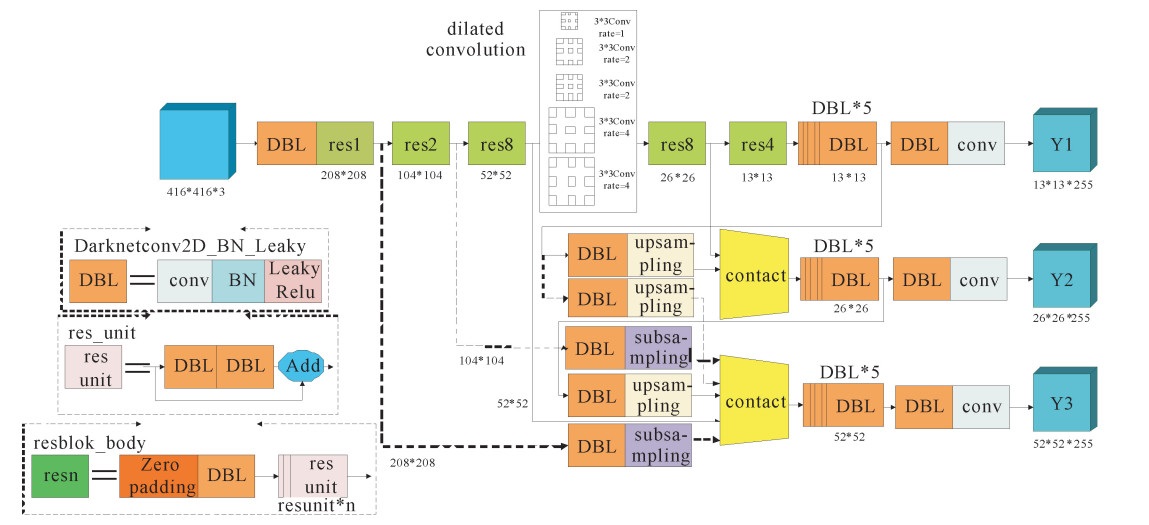
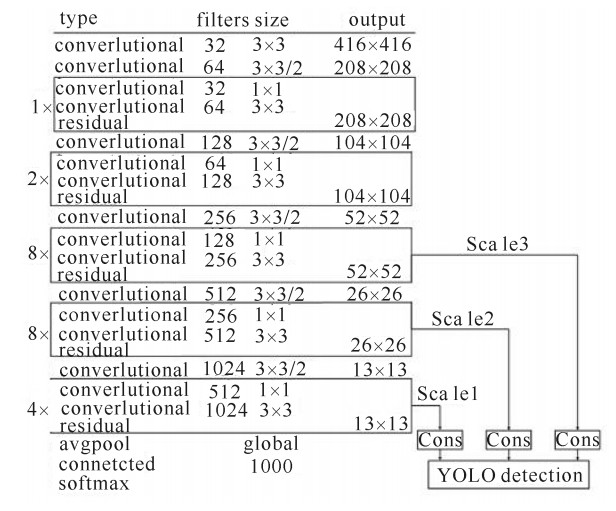
摘要: 针对辐射环境下核废料检测准确率低的问题,提出一种基于深度卷积神经网络的辐射环境下核废料检测算法Dense-Dilated-YOLO V3。实验结果表明,Dense-Dilated-YOLO V3在不增加参数的情况下扩大了网络感受野,也有效避免图像信息的损失,同时能够在核辐射环境下提取到更多的目标细节特征,对辐射环境下目标检测的准确率可达93.29%,比原算法提高5.53%,召回率可达91.73%,提高了8.28%,有效解决了复杂辐射环境下核废料检测准确率低的问题,为辐射环境下核废料检测提供了新的途径。Abstract: Aiming at the low accuracy of nuclear waste detection under radiation environment, this paper proposes a nuclear waste detection algorithm named Dense-Dilated-YOLO V3 based on deep learning convolution neural network. The experimental results show that Dense-Dilated-YOLO V3 increases the network receptive field without increasing the parameters, effectively avoids the loss of image information, extracts more detailed features of the target in the radiation environment, and accurately detects the target under radiation environment. The rate reached 93.29%, which was 5.53% higher than the original algorithm, and the recall rate reached 91.73%, with an increase of 8.28%. It solved the problem of low accuracy of nuclear waste detection under complex radiation environment, and has better detection effect. It provides a new approach for nuclear waste detection.
-
Key words:
- deep learning /
- convolutional neural network /
- YOLO V3 /
- nuclear waste /
- target detection
-

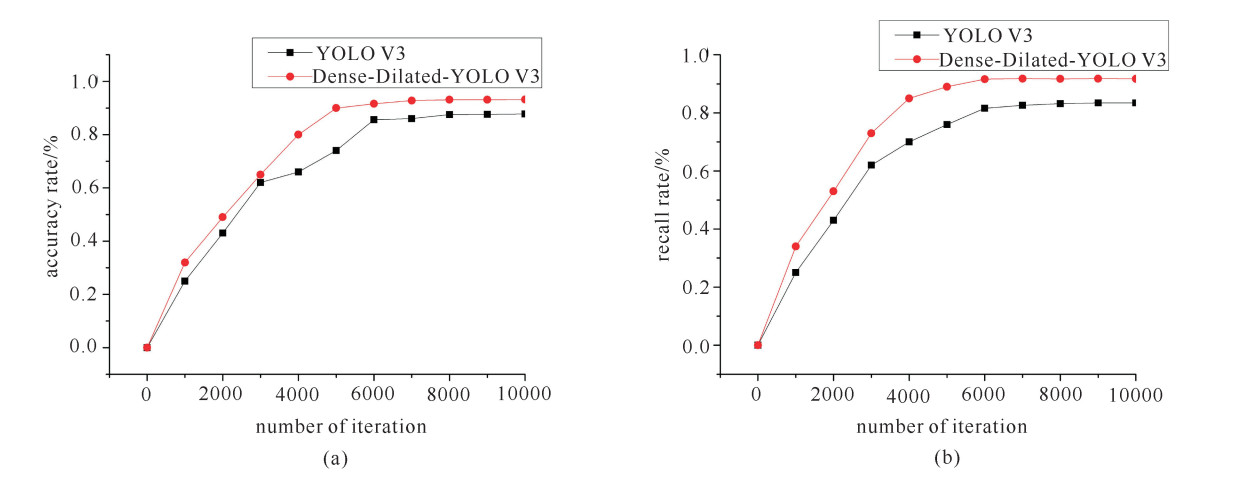
图 5 YOLO V3和Dense-Dilated-YOLO V3检测效果对比图
Figure 5. Detection effect comparison chart of YOLO V3 and Dense-Dilated-YOLO V3
表 1 网络性能结果对比表
Table 1. The comparison table of Network performance result
evaluation index Accuracy/% RECALL/% IOU/ % MAP/ % YOLO V3 87.76 83.45 83.97 82.58 Dense-Dilated-YOLO V3 93.29 91.73 88.64 90.34  下载: 导出CSV
下载: 导出CSV
-
[1] 王德娇, 史晋芳, 吴倩, 等. 一种混合降噪方法在辐射图像降噪处理中的应用[J]. 机械设计与制造, 2017(1): 97-100. https://www.cnki.com.cn/Article/CJFDTOTAL-JSYZ201701026.htmWang Dejiao, Shi Jinfang, Wu Qian, et al. Application of integrative denoising method for radiation image denoising. Mechanical Design and Manufacturing, 2017(1): 97-100 https://www.cnki.com.cn/Article/CJFDTOTAL-JSYZ201701026.htm [2] 仝跃, 黄宏伟, 张东明, 等. 高放废物处置地下实验室建设期风险接受准则[J]. 中国安全科学学报, 2017, 27(2): 151-156. https://www.cnki.com.cn/Article/CJFDTOTAL-ZAQK201702028.htmTong Yue, Huang Hongwei, Zhang Dongming, et al. Research on risk acceptance criteria for construction of HLW geological disposal URL. China Safety Science Journal, 2017, 27(2): 151-156 https://www.cnki.com.cn/Article/CJFDTOTAL-ZAQK201702028.htm [3] 阙渭焰. 复杂辐射环境与武器装备试验评估[J]. 强激光与粒子束, 2015, 27: 103201. doi: 10.11884/HPLPB201527.103201Que Weiyan. Military system radiation environments effects test and evaluation. High Power Laser and Particle Beams, 2015, 27: 103201 doi: 10.11884/HPLPB201527.103201 [4] Girshick R, Donahue J, Darrelland T, et al. Rich feature hierarchies for object detection and semantic segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. 2014. [5] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 39(6): 1137-1149. [6] Girshick R. Fast R-CNN[C]//Proc of IEEE International Conference on Computer Vision. 2015: 1440-1448. [7] He K, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//IEEE International Conference on Computer Vision. 2017: 2980-2988. [8] Liu W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. 2016: 21-37. [9] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//IEEE Computer Vision and Pattern Recognition. 2016: 779-788. [10] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger[C]//IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6517-6525. [11] Redmon J, Farhadi A. YOLOv3: An incremental improvement[C]//IEEE Conference on Computer Vision and Pattern Recognition. 2018: 89-95. [12] 王琳, 卫晨, 李伟山, 等. 结合金字塔池化模块的YOLOv2的井下行人检测[J]. 计算机工程与应用, 2019, 55(3): 133-139. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201903022.htmWang Lin, Wei Cheng, Li Weishan, et al. Pedestrian detection based on YOLOv2 with pyramid pooling module in underground coal mine. Computer Engineering and Applications, 2019, 55(3): 133-139 https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201903022.htm [13] 周云成, 许童羽, 邓寒冰, 等. 基于面向通道分组卷积网络的番茄主要器官实时识别[J]. 农业工程学报, 2018, 337(10): 161-170. https://www.cnki.com.cn/Article/CJFDTOTAL-NYGU201810019.htmZhou Yuncheng, Xu Tongyu, Deng Hanbing, et al. Real-time recognition of main organs in tomato based on channel wise group convolutional network. Transactions of the Chinese Society of Agricultural Engineering, 2018, 337(10): 161-170 https://www.cnki.com.cn/Article/CJFDTOTAL-NYGU201810019.htm [14] 吴天舒, 张志佳, 刘云鹏, 等. 结合YOLO检测和语义分割的驾驶员安全带检测[J]. 计算机辅助设计与图形学学报, 2019, 31(1): 126-131.Wu Tianshu, Zhang Zhijia, Liu Yunpeng, et al. Driver seat belt detection based on YOLO detection and semantic segmentation. Journal of Computer-Aided Design and Computer Graphics, 2019, 31(1): 126-131 [15] 李策, 张亚超, 蓝天, 等. 一种高分辨率遥感图像视感知目标检测算法[J]. 西安交通大学学报, 2018, 52(6): 14-21. https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT201806002.htmLi Ce, Zhang Yachao, Lan Tian, et al. An object detection algorithm with visual perception for high-resolution REM. Journal of Xi'an Jiaotong University, 2018, 52(6): 14-21 https://www.cnki.com.cn/Article/CJFDTOTAL-XAJT201806002.htm [16] Jégou S, Drozdzal M, Vazquez D, et al. The one hundred layers tiramisu: Fully convolutional DenseNets for semantic segmentation[C]//Computer Vision and Pattern Recognition. 2017: 1175-1183. [17] Kudo Y, Aoki Y. Dilated convolutions for image classification and object localization[C]//IEEE Fifteenth Iapr International Conference on Machine Vision Applications. 2017: 452-455. 期刊类型引用(2)
1. 左靖凡,李士锋,吴洋,黄华,孙利民,宋法伦. 带双腔反射器的X波段低磁场过模相对论返波管振荡器. 强激光与粒子束. 2024(03): 63-68 .  本站查看
本站查看2. 张晓微,李永东,白现臣,梁玉钦. 宽间隙反射器相对论返波管同频高阶模式抑制. 强激光与粒子束. 2015(07): 127-132 . 本站查看其他类型引用(1)
-

 点击查看大图
点击查看大图
图(5) / 表(1)
计量
- 文章访问数: 1404
- HTML全文浏览量: 216
- PDF下载量: 44
- 被引次数: 3
